
Brown CS Alum Ani Kristo And Collaborators Are 2022 Sort Benchmark Winners
- Posted by Jesse Polhemus
- on April 21, 2023
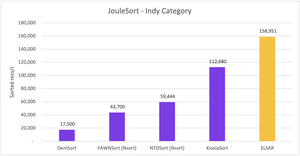
Developed in 1994 by Turing Award winner Jim Gray, Sort Benchmark is an annual competition in which researchers attempt to rapidly sort a terabyte of data. Brown CS alum Ani Kristo, now at Meta, and Adjunct Associate Professor Tim Kraska, now at Massachusetts Institute of Technology, along with collaborator Padmanabhan S. Pillai of Intel Labs, have recently won the contest’s top prize in the JouleSort Indy category, which measures energy efficiency, using a Learned Sorting algorithm. Their implementation, ELSAR, showed that one can sort a terabyte using 62,912 (+/- 372) joules with a runtime of 618.1 (+/- 5) seconds on average, and their results were 1.4 times faster than those of the prior winner.
Ani says that his team took research from the early part of his doctoral work at Brown CS and translated them for large-scale data sorting. “ELSAR’s core value proposition,” he explains, “is that we’re borrowing ideas from machine learning [ML] to estimate properties of the data that can inform our sorting algorithm and accelerate certain steps that would otherwise be bottlenecks for traditional sorting algorithms.”
Their use of ML techniques, Ani explains, provided a powerful predictive tool. Their solution was to look at a small sample of the data and use these techniques to make predictions about what the entire dataset will be like. Once that estimate was in place, ELSAR optimized the sorting algorithm to make it faster, allowing for better partitioning and concatenation instead of merging in the traditional way.
Another interesting aspect of the project is that the researchers had to develop their own hardware expertise, building the energy-efficient machine used in the contest, carefully selecting energy-efficient system components.
“The rationale behind sorting’s energy efficiency,” Ani explains, “is that it reduces operational costs in data centers, which is enormous for large-scale software companies. Optimizations in this area can also have a huge environmental impact because they reduce energy costs.”
“I’ve closed this chapter of my PhD,” he tells us, “but I’m very proud that our research can be applied to other components in the database world. Our work is at the intersection of machine learning and databases, and I think we’ve shown that it has a lot of value for future researchers. I’m interested to see what’s going to come next.”
The full list of winners is available here.
For more information, click the link that follows to contact Brown CS Communications Manager Jesse C. Polhemus.


